Finding bugs at limited scope programs (Single Domain Websites)
Hi hunters, I am back with another write-up. Finding bugs in large scope is easy and its provide a large attack surface for hunters to test the applications in many different ways but when it comes to a small or limited scope then it is quite difficult to hunting for bugs.
I know if you are a beginner then it is difficult for you to find endpoints. Please read Web Application Hacker’s Handbook 2nd, Chapter 4, Page -98 to know more about endpoints.

It is not possible to write and demonstrate about each and every endpoint in single article. I will try to explain some of them.
HTTP headers
As we know the HTTP headers are used to pass additional information between the clients and the server through the request and response header. We can try to put payloads at different types of headers. I will demonstrate the Referer and User-Agent headers, if you want to know more about other headers then read at references.
RCE via Referer Header
One day I was playing a CTF challenge. It was vulnerable to LFI (Local file Inclusion). Just for curiosity I google the `LFI to RCE` and found some write-up about how an attacker can escalate the LFI vulnerability to RCE via Referer header.
While testing I noticed I was able to access the access logs of server via file:///proc/self/fd/{number} and found request reflected at response. I immediately put payload <?php system(‘ id ‘);?> at Referer and achieve RCE successfully.

SQL injection via User-Agent Header
The User-Agent is a request header that allows a characteristic string that allows network protocol peers to identify the Operating System and Browser of the web-server. Your browser sends the user agent to every website you connect to. If application stores the User-Agent at database directly without any sanitization then it is possible to execute database query via user-agent header.
I Setup my own server. I wrote a script to store each user browser’s data who browse the website. I put payload ‘, (select*from(select (sleep(5)))a))# at User-agent header and successfully execute sleep query. I was able to demonstrate that because application stores user-agents directly into the server without any validation.

HTTP request methods
HTTP defines a set of request methods to indicate the desired action to be performed for a given resource. Although they can also be nouns, these request methods are sometimes referred to as HTTP verbs. Each of them implements a different semantic, but some common features are shared by a group of them: e.g. a request method can be safe, idempotent, or cacheable.

As we know each request methods has perform different types of action. If server did not configured properly then it may be lead to security vulnerability
Change request methods
Before play around request methods, setup your proxy application (Burp/Zap proxy) and browse the application each features. Now observe each request manually in proxy history. You can change the each request methods in each request (Like POST to GET or any other), you can also try to brute-force the request methods and remember you must have to monitor the response of each request.
CSRF bypass via GET method
Some applications correctly validate the token when the request uses the POST method but skip the validation when the GET method is used.
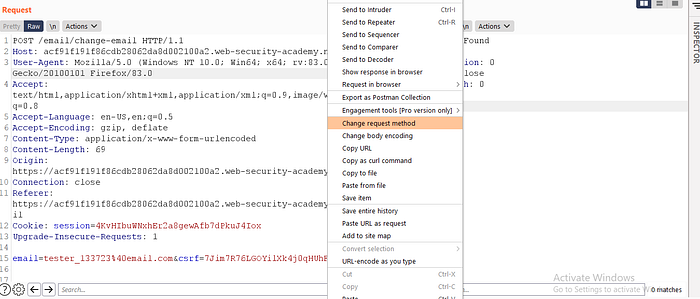
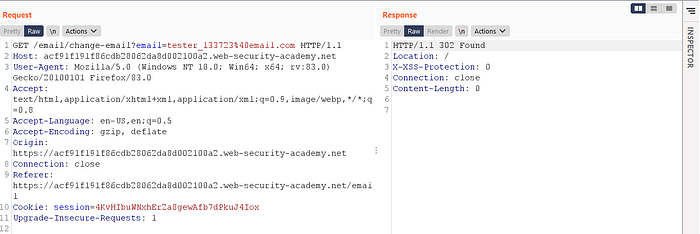
In this situation, the attacker can switch to the GET method to bypass the validation and deliver a CSRF attack:
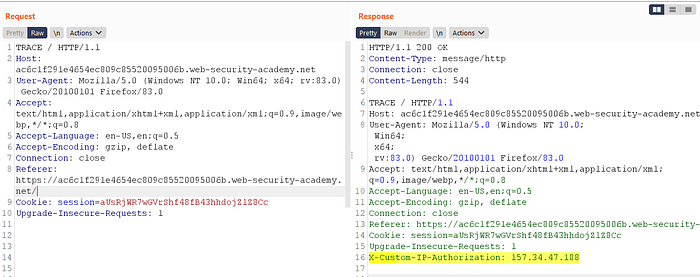
Information Disclosure via TRACE method
Websites are sometimes vulnerable as a result of improper configuration. This is especially common due to the widespread use of third-party technologies, whose vast array of configuration options are not necessarily well-understood by those implementing them.
In other cases, developers might forget to disable various debugging options in the production environment. For example, the HTTP TRACE method is designed for diagnostic purposes. If enabled, the web server will respond to requests that use the TRACE method by echoing in the response the exact request that was received. This behavior is often harmless, but occasionally leads to information disclosure, such as the name of internal authentication headers that may be appended to requests by reverse proxies.
Conclusion
Finding bugs is not easy at limited scope(Single domain website) but if you test each and every endpoint manually. It may increase your chance to catch valid bugs. Put your payloads everywhere and observe the response, we know it takes time but they pay us for our efforts and creativity.
References
https://www.geeksforgeeks.org/http-headers/
https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods
https://resources.infosecinstitute.com/topic/sql-injection-http-headers/
https://hackerone.com/reports/297478
https://hackerone.com/reports/1018621
https://www.geeksforgeeks.org/http-headers-user-agent
https://medium.com/@Hardik.Solanki/lfi-to-rce-by-injecting-access-log-ebe4bc789bef
